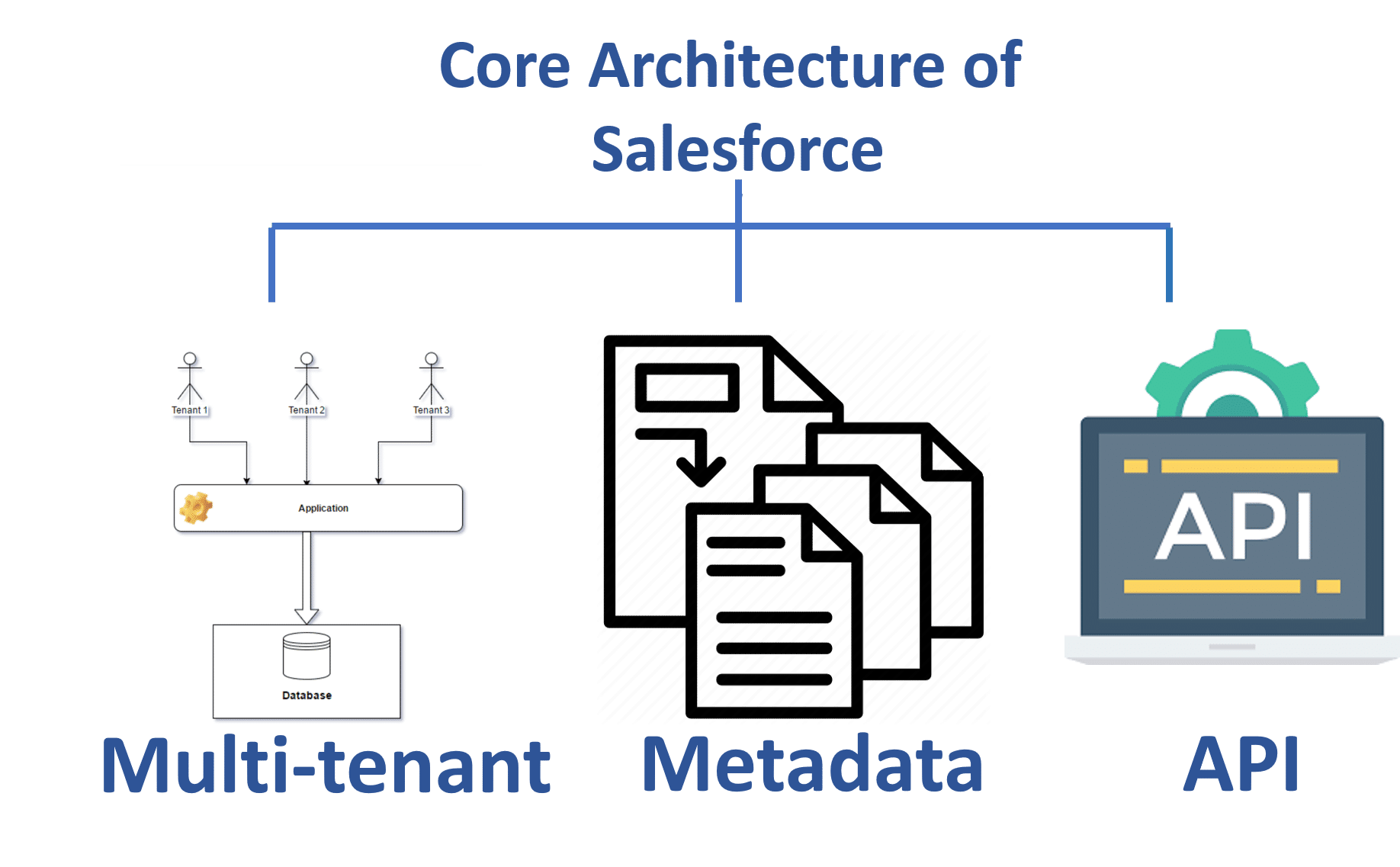
Multitenant Data Model
Building a cloud application development platform that attempts to manage a vast, ever-changing set of actual database structures on behalf of each application and tenant would be next to impossible as the service grows. Instead, the Force.com storage model manages virtual database structures using a set of metadata, data, and pivot tables, as illustrated in the following figure.

When you create application schemas, the UDD keeps track of metadata concerning the objects, their fields, their relationships, and other object attributes. Meanwhile, a few large database tables store the structured and unstructured data for all virtual tables. A set of related multitenant indexes, implemented as simple pivot tables with denormalized data, make the combined data set extremely functional. The following sections explain each type of component in more detail.
Multitenant Metadata
Force.com has two core internal tables that it uses to manage metadata that corresponds to a tenant’s schema objects: MT_Objects and MT_Fields. (Please note that, for clarity, the actual names of Force.com system tables and columns are not necessarily cited in this paper.)
- The MT_Objects system table stores metadata about the tables that an organization defines for an application, including a unique identifier for an object (ObjID), the organization (OrgID) that owns the object, and the name given to the object (ObjName).
- The MT_Fields system table stores metadata about the fields (columns) that an organization defines for each object, including a unique identifier for a field (FieldID), the organization (OrgID) that owns the encompassing object, the object that contains the field (ObjID), the name of the field (FieldName), the field’s datatype, a Boolean value to indicate if the field requires indexing (IsIndexed), and the position of the field in the object relative to other fields (FieldNum).
Multitenant Data
The MT_Data system table stores the application-accessible data that maps to all organization-specific tables and their fields, as defined by metadata in MT_Objects and MT_Fields. Each row includes identifying fields, such as a global unique identifier (GUID), the organization that owns the row (OrgID), and the encompassing object identifier (ObjID). Each row in the MT_Data table also has a Name field that stores a “natural name” for corresponding records; for example, an Account record might use “Account Name,” a Case record might use “Case Number,” and so on.
Value0 … Value500 flex columns, otherwise known as slots, store application data that maps to the tables and fields declared in MT_Objects and MT_Fields, respectively; all flex columns use a variable-length string datatype so that they can store any structured type of application data (strings, numbers, dates, etc.). As the following figure illustrates, no two fields of the same object can map to the same slot in MT_Data for storage; however, a single slot can manage the information of multiple fields, as long as each field stems from a different object.

MT_Fields can use any one of a number of standard structured datatypes such as text, number, date, and date/time, as well as special-use, rich-structured datatypes such as picklist (enumerated field), auto-number (auto-incremented, system-generated sequence number), formula (read-only derived value), master-detail relationship (foreign key), checkbox (Boolean), email, URL, and others. MT_Fields can also be required (not null) and have custom validation rules (for example, one field must be greater than another field), both of which Force.com enforces.
When an organization declares or modifies an object, Force.com manages a row of metadata in MT_Objects that defines the object. Likewise, for each field, Force.com manages a row in MT_Fields, including metadata that maps the field to a specific flex column in MT_Data for the storage of corresponding field data. Because Force.com manages object and field definitions as metadata rather than actual database structures, the system can tolerate online multitenant application schema maintenance activities without blocking the concurrent activity of other tenants and users. By comparison, online table redefinition for traditional relational database systems typically requires laborious, complicated processes and scheduled application downtime.
As the simplified representation of MT_Data in the previous figure shows, flex columns are of a universal datatype (variable-length string), which permits Force.com to share a single flex column among multiple fields that use various structured datatypes (strings, numbers, dates, etc.).
Force.com stores all flex column data using a canonical format, and uses underlying database system datatype-conversion functions (e.g., TO_NUMBER, TO_DATE, TO_CHAR) as necessary when applications read data from and write data to flex columns.
Although not shown in the previous figure, MT_Data also contains other columns. For example, there are four columns to manage auditing data, including which user created a row and when that row was created, and which user last modified a row and when that row was last modified. MT_Data also contains an IsDeleted column that Force.com uses to indicate when a row has been deleted.
Force.com also supports the declaration of fields as character large objects (CLOBs) to permit the storage of long text fields of up to 32,000 characters. For each row in MT_Data that has a CLOB, Force.com stores the CLOB out of line in a table called MT_Clobs, which the system can join with corresponding rows in MT_Data as necessary.
Note: Force.com also stores CLOBs in an indexed form outside of the database for fast text searches. See later in this paper for more information about Force.com’s text search engine.
Multitenant Indexes
Force.com automatically indexes various types of fields to deliver scalable performance—without you ever having to think about it. This section explains more about the unique way that Force.com manages index data for multiple tenants.
Traditional database systems rely on native database indexes to quickly locate specific rows in a database table that have fields matching a specific condition. However, it is not practical to create native database indexes for the flex columns of MT_Data because Force.com uses a single flex column to store the data of many fields with varying structured datatypes. Instead, Force.com manages an index of MT_Data by synchronously copying field data marked for indexing to an appropriate column in an MT_Indexes pivot table.
MT_Indexes contains strongly typed, indexed columns such as StringValue, NumValue, and DateValue that Force.com uses to locate field data of the corresponding datatype. For example, Force.com would copy a string value in an MT_Data flex column to the StringValue field in MT_Indexes, a date value to the DateValue field, etc. The underlying indexes of MT_Indexes are standard, non-unique database indexes. When an internal system query includes a search parameter that references a structured field in an object, Force.com’s custom query optimizer uses MT_Indexes to help optimize associated data access operations.
Note: Force.com can handle searches across multiple languages because the system uses a case-folding algorithm that converts string values to a universal, case-insensitive format. The StringValue column of the MT_Indexes table stores string values in this format. At runtime, the query optimizer automatically builds data access operations so that the optimized SQL statement filters on the corresponding case-folded StringValue, which in turn corresponds to the literal provided in the search request.
Force.com lets an organization indicate when a field in an object must contain unique values (case-sensitive or case-insensitive). Considering the arrangement of MT_Data and shared usage of the Value columns for field data, it is not practical to create unique database indexes for the object. (This situation is similar to the one discussed in the previous section for non-unique indexes.)
To support uniqueness for custom fields, Force.com uses the MT_Unique_Indexes pivot table; this table is very similar to the MT_Indexes table, except that the underlying native database indexes of MT_Unique_ Indexes enforce uniqueness. When an application attempts to insert a duplicate value into a field that requires uniqueness, or an administrator attempts to enforce uniqueness on an existing field that contains duplicate values, Force.com relays an appropriate error message to the application.
In rare circumstances, Force.com’s external search engine (explained later in this paper) can become overloaded or otherwise unavailable, and may not be able to respond to a search request in a timely manner. Rather than returning a disappointing error to a user that has requested a search, Force.com falls back to a secondary search mechanism to furnish reasonable search results.
A fall-back search is implemented as a direct database query with search conditions that reference the Name field of target records. To optimize global object searches (searches that span tables) without having to execute potentially expensive union queries, Force.com maintains a MT_Fallback_Indexes pivot table that records the Name of all records. Updates to MT_Fallback_Indexes happen synchronously as transactions modify records so that fall-back searches always have access to the most current database information.
The MT_Name_Denorm table is a lean data table that stores the ObjID and Name of each record in MT_Data. When an application needs to provide a list of records involved in a parent/child relationship, Force.com uses the MT_Name_Denorm table to execute a relatively simple query that retrieves the Name of each referenced record for display in the app, say, as part of a hyperlink.
Multitenant Relationships
Force.com provides “relationship” datatypes that an organization can use to declare relationships (referential integrity) among tables. When an organization declares an object’s field with a relationship type, Force.com maps the field to a Value field in MT_Data, and then uses this field to store the ObjID of a related object.
To optimize join operations, Force.com maintains an MT_Relationships pivot table. This system table has two underlying database unique composite indexes that allow for efficient object traversals in either direction, as necessary.
Multitenant Field History
With just a few mouse clicks, Force.com provides history tracking for any field. When a tenant enables auditing for a specific field, the system asynchronously records information about the changes made to the field (old and new values, change date, etc.) using an internal pivot table as an audit trail.